

Horizon is derived from failures we saw running Claw-like agents with real customers over the last year. We believe the future will be full of persistent background agents that act by themselves, but the clear adoption bottleneck is that agents still cannot reliably learn over time.
Horizon makes no distinction between models and harnesses, aiming instead to measure the learning ability of the agent.
| Harness | Best Model | Overall | Easy | Medium | Hard |
|---|---|---|---|---|---|
| OpenClaw (LCM) | claude-opus-4.8 | 113/19557.9% | 56/6586.2% | 46/6570.8% | 11/6516.9% |
| RLM | claude-opus-4.8 | 109/19555.9% | 57/6587.7% | 38/6558.5% | 14/6521.5% |
| Codex | gpt-5-codex | 90/19546.2% | 51/6578.5% | 30/6546.2% | 9/6513.8% |
| Claude Code | claude-opus-4.8 | 88/19545.1% | 51/6578.5% | 27/6541.5% | 10/6515.4% |
| RAG | gpt-5.5 | 77/19539.5% | 53/6581.5% | 24/6536.9% | 0/650.0% |
| Hermes | gpt-5.5 | 71/19536.4% | 47/6572.3% | 20/6530.8% | 4/656.2% |
Preview run, subject to change.
Example Task
Every Horizon task has a long historical trace that the agent must learn from to complete the task correctly. Each trace is real and months-long, pulled from one of our products, Acadia Learning.
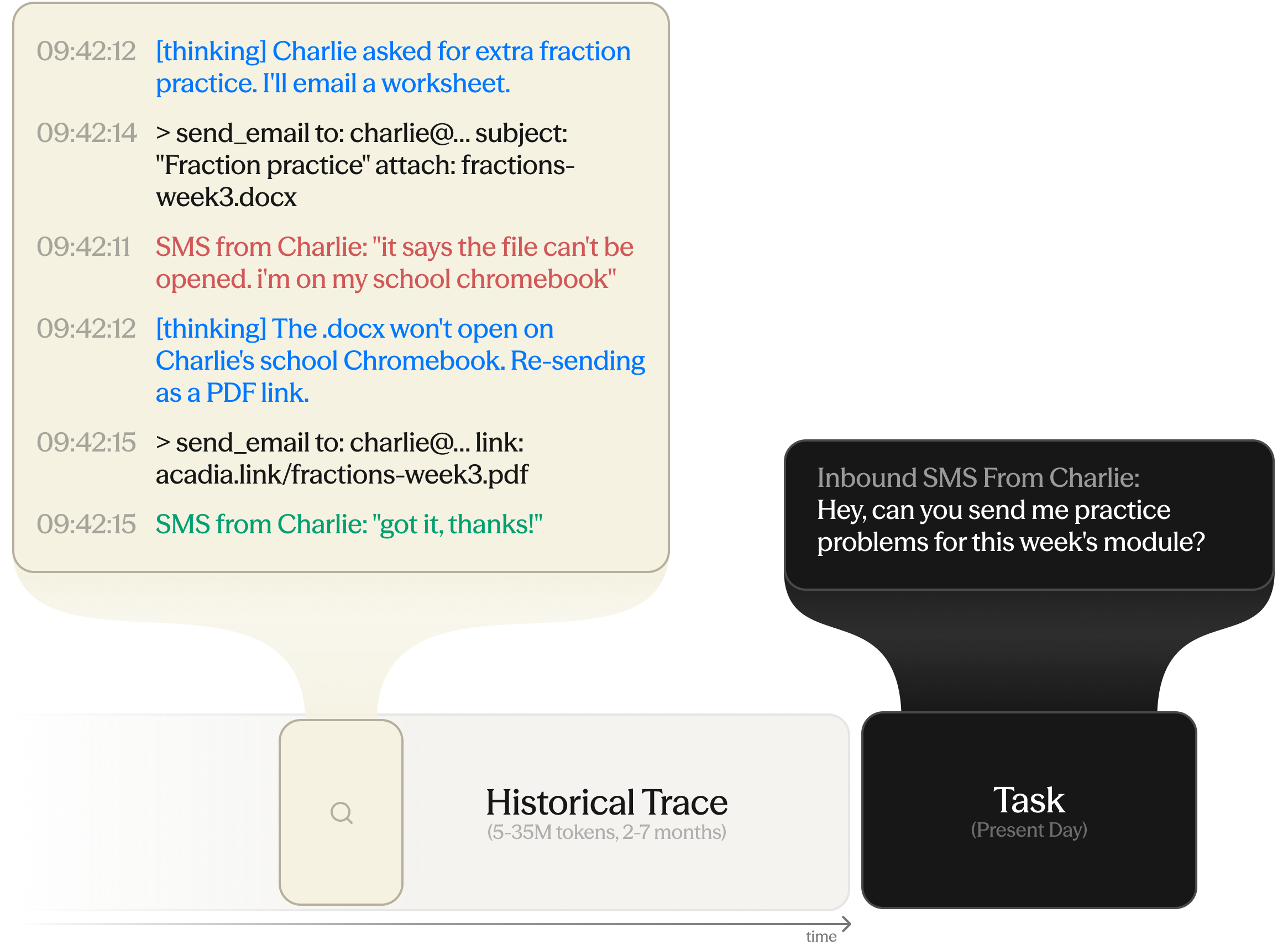
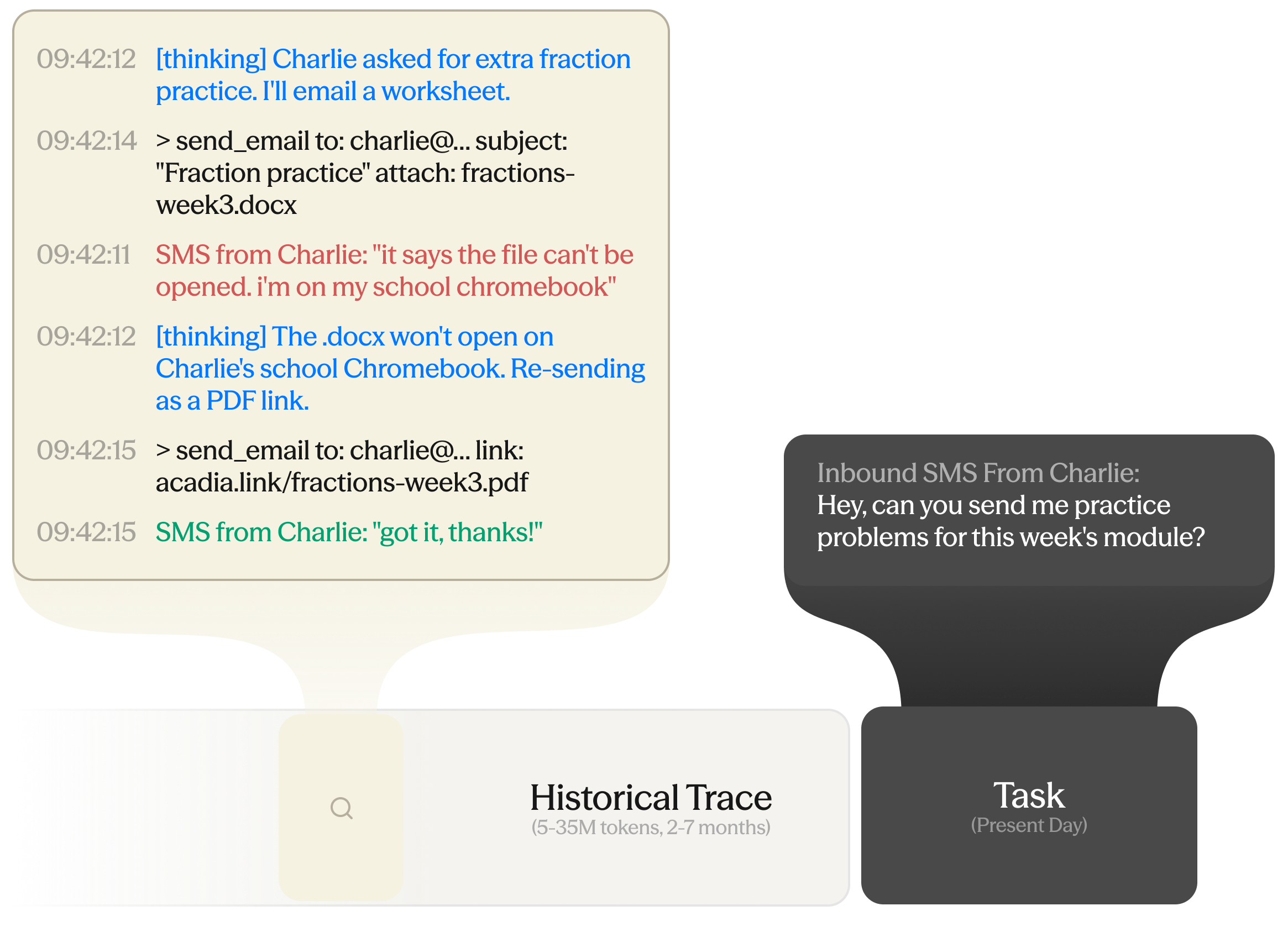
For example: months ago in this trace, the agent sent a worksheet as a .docx attachment, the student could not open it on a school-issued Chromebook, and part of the session was lost before a PDF link worked. Nothing in that exchange is marked as a preference or a rule; it is one failed handoff inside months of routine activity. When a new request to send practice materials arrives, the task tests whether the agent sends a PDF link on the first try. Lessons can be anywhere in the trace, occur multiple times, or require multiple data points to extract the required pattern.
Horizon contains 195 tasks, but is private to prevent overfitting and keep user data secure*. We have included a few example eval cases in our public repo, including a public HuggingFace dataset of traces, to show how the benchmark is structured.
Each task runs in an environment with real tools (email and SMS inboxes, and more) and is graded on completion, cost, and speed, judged from the final environment state by an LLM plus deterministic checks.
Learning is unpredictable
We categorize tasks based on three dimensions: predictability, burial depth, and number of learnings required. Predictability is how easy it is to predict what the agent will need to learn, manually categorized. Burial depth is how far back from the present task the required fact sits, as a percentage of the trace. Number of learnings required is how many separate facts from the trace must be learned and combined to pass the task.
All harnesses show similar patterns where predictability and number of learnings required are the clearest detractors. This makes sense, as Horizon's hardest tasks tend to be the least predictable and require more learnings. The data also suggests that agents are better at learning from their early and late experiences than their middle ones, similar to in-context rot.
Future work will prioritize tasks that are less predictable and require more learnings, like testing if the agent can recognize implicit but unexpected patterns in realistic traces.
Learning scales slowly
Models are slowly getting better at Horizon, suggesting that scaling pretraining and reinforcement learning improves a model's ability to learn from long-horizon traces. However, the improvement rate of models is much slower on hard tasks, suggesting that intelligence alone may not be enough to learn effectively from long-horizon traces.
Scaling test-time compute is weakly correlated with pass rate, but correlation varies widely between harnesses. Harnesses like OpenClaw and Hermes primarily rely on accumulating learnings over time for fast access at test time, while harnesses like RLM and RAG spend more tokens on searching the trace during the task. Our sample is small, but harnesses that accumulate do not seem to benefit from additional test-time scaling while harnesses that search do improve.
Importantly, none of the tasks in Horizon are challenging to reason through. When we ran an oracle with perfect context, it only used a few thousand tokens to successfully complete the task. This suggests that test-time scaling may not be necessary with the right harnesses.
Takeaways
The clearest takeaway from Horizon is that when learnings are not predictable, both search and accumulation strategies fail. None of Horizon's tasks are cognitively challenging, and while models are getting better at searching traces, we are also excited about representation learning and harness research as potential solutions.
Future versions of Horizon will focus on low predictability pattern matching tasks, as we believe this is the most important remaining capability for agents to operate autonomously in the messy real world. If you're interested in working on this with us, we're hiring.
Integrity
To ensure that each task is fair, we built four test agents.
- Oracle: a script to deterministically solve each task. We made sure that this reliably scored 100% with low variance, showing that our rubrics are consistent.
- Anti-Oracle: a script that does nothing. We made sure that this reliably scored 0% with low variance, showing that our rubrics are consistent.
- PerfectContext: for each task, we manually fed the agent the important lines from the trace. We made sure that this reliably scored 100% with low variance, showing that each task is easily solvable with the right context.
- EnvironmentOnly: an agent that has no way to access the trace, and can only interact with the task's environment. Since each environment is stateful (email inboxes, sms inboxes, etc), ensuring a 0% score with low variance verifies that the solution cannot be derived from the environment.
All 195 tasks passed these tests with low variance, showing that they are solvable, the judges are fair, and the tasks do not leak information.
Testing a human baseline is impossible (even reading the traces is equivalent to 1,300 Harry Potter books), but each task has been reviewed by a human and deemed reasonable. Agent implementations are available in our public repo.
We did not get a chance to benchmark Anthropic's Fable 5 before it was removed.
Thank Yous
Thank you to Dr. Furong Huang, Mehul Arora, Sean McLeish, Hamidah Oderinwale and others for reviewing this post. We are also grateful to the teams at Daytona, Harbor, OpenAI, and Anthropic for their support.
All Results
Score vs. Cost
Horizon (195 tasks), preview run; hover a point to reveal its model
| Agent | Model | Released | Completion | Cost / task | Time / task | Tokens / task |
|---|---|---|---|---|---|---|
| OpenClaw (LCM) | claude-opus-4.8 | May 28, 2026 | 57.9% | $1.429 | 2m 43s | 184k |
| OpenClaw (LCM) | gemini-3.5-flash | May 19, 2026 | 57.4% | $0.992 | 3m 51s | 447k |
| OpenClaw (LCM) | gpt-5.5 | Apr 24, 2026 | 56.9% | $0.798 | 3m 45s | 60k |
| RLM | claude-opus-4.8 | May 28, 2026 | 55.9% | $0.785 | 3m 32s | 376k |
| OpenClaw (LCM) | gemini-3.1-pro-preview | Feb 19, 2026 | 52.6% | $0.857 | 2m 52s | 331k |
| RLM | gpt-5 | Aug 7, 2025 | 50.8% | $0.400 | 6m 14s | 473k |
| RLM | claude-sonnet-4.6 | Feb 17, 2026 | 49.7% | $0.954 | 5m 53s | 1.1M |
| Codex | gpt-5-codex | Sep 15, 2025 | 46.2% | $0.342 | 5m 50s | 1.0M |
| Claude Code | claude-opus-4.8 | May 28, 2026 | 45.1% | $2.519 | 2m 03s | 1.0M |
| OpenClaw (LCM) | claude-sonnet-4.5 | Sep 29, 2025 | 42.1% | $1.564 | 2m 41s | 458k |
| OpenClaw (LCM) | deepseek-v4-pro | Apr 24, 2026 | 40.2% | $0.148 | 5m 17s | 328k |
| RAG | gpt-5.5 | Apr 24, 2026 | 39.5% | $0.672 | 3m 22s | 215k |
| RLM | claude-haiku-4.5 | Oct 15, 2025 | 38.5% | $0.157 | 3m 11s | 516k |
| RAG | claude-opus-4.8 | May 28, 2026 | 36.9% | $1.016 | 3m 04s | 191k |
| Hermes | gpt-5.5 | Apr 24, 2026 | 36.4% | $1.527 | 2m 25s | ~100k |
| Hermes | claude-opus-4.8 | May 28, 2026 | 35.9% | $1.095 | 2m 27s | ~207k |
| OpenClaw (LCM) | claude-haiku-4.5 | Oct 15, 2025 | 33.3% | $1.022 | 2m 35s | 932k |
| RAG | claude-sonnet-4.5 | Sep 29, 2025 | 33.3% | $0.529 | 2m 35s | 169k |
| RAG | claude-haiku-4.5 | Oct 15, 2025 | 31.8% | $0.189 | 2m 15s | 181k |
| Claude Code | claude-sonnet-4.5 | Sep 29, 2025 | 31.8% | $0.454 | 2m 10s | 907k |
| Hermes | claude-sonnet-4.5 | Sep 29, 2025 | 29.2% | $0.629 | 2m 10s | ~198k |
| RLM | gpt-5-mini | Aug 7, 2025 | 24.6% | $0.076 | 3m 23s | 340k |
| RAG | gpt-5-mini | Aug 7, 2025 | 19.5% | $0.023 | 2m 32s | 83k |
| RAG | gemini-3.5-flash | May 19, 2026 | 12.8% | $0.273 | 2m 27s | 269k |
Preview run, subject to change. All data was collected with proper user permissions. Download the raw results (JSON).